Go语言精进之路
项目结构
以构建二进制可执行文件为目的
1 | GoProject |
cmd目录存放项目要构建的可执行文件对应的main包的源文件
cmd目录下的各app的main包将整个项目的依赖连接在一起
并且通常来说main包应该很简洁
我们会在main包中做一些命令行参数解析 资源初始化 日志设施初始化 数据库连接初始化等工作
之后就会将程序的执行权限交给更高级的执行控制对象
有一些Go项目将cmd这个名字改为app 但其功用并没有变
Makefile是项目构建工具的脚本 Go没有内置的例如CMake等级别的项目构建工具
在Go典型项目中 项目构建工具的脚本一般放在项目顶层目录下
go.mod go.sum Go 包依赖管理 使用的配置文件
pkg目录 存放项目自身要使用并且同样也是可执行文件对应main包要依赖的库文件
该目录下的包可以被外部项目引用 算是项目导出包的一个聚合
以只构建库为目的
1 | GoLibProject |
为何去除cmd和pkg两个子目录
因为只构建库所以没必要存放二进制文件main包源文件的cmd目录
因为Go库项目的初衷一般是对外部暴露API 因此没必要将其单独聚合在pkg目录下
若一些包不想暴露给外部引用 仅限项目内部使用 可以引入internal包机制实现
在顶层加入一个internal目录 将不想暴露到外部的包都放在该目录下
代码风格
使用gofmt即可帮助规范化代码 但gofmt工具无法自动删减文件头部的包导入目标
但官方拥有goimports 可根据源码的最新变动自动从导入包列表中增删包
命名惯例
命名包
包package以小写形式的某个单词命名
包名可以不唯一 但尽量与包导入路径的最后分段保持一致
命名变量
小驼峰拼写法 lowCamelCase
变量名字中不要带有类型信息
命名接口
Go语言中的接口是Go在编程语言层面的一个创新,它为Go代码提供了强大的解耦合能力,因此良好的接口类型设计和接口组合是Go程序设计的静态骨架和基础。良好的接口设计自然离不开良好的接口命名。在Go语言中,对于接口类型优先以单个单词命名。对于拥有唯一方法(method)或通过多个拥有唯一方法的接口组合而成的接口,Go语言的惯例是用“方法名+er”命名。比如:
1 | type Writer interface { |
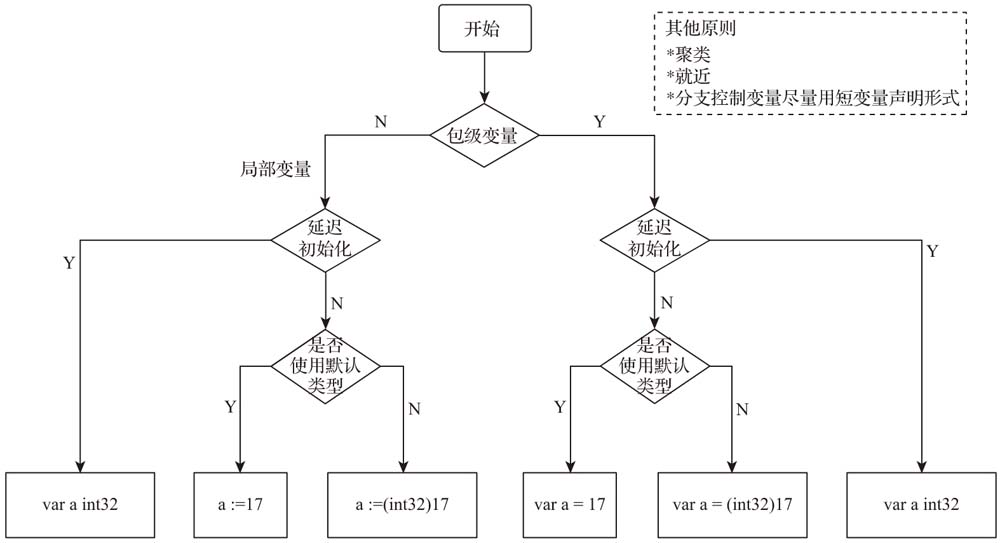
使用一致的变量声明形式
Go语言有两类变量
包级变量 在package级别可见的变量 若是导出变量则该包级变量也可以被视为全局变量
局部变量 函数或方法体内声明的变量 仅在函数和方法体内可见
包级变量声明形式
声明的同时显示初始化 若不初始化 则会被保证拥有同类型的”零值”
1 | //第一种 |
官方更推荐后者 尤其是将这些变量放在同一个var块中声明时
并且将同一类型的声明放在同一个var块中
1 | var ( |
无类型常量
定义常量使用const关键词
1 | const ( |
绝大多数情况下 Go常量在声明时并不显式指定类型
即无类型常量
1 | const ( |
有类型常量的烦恼
为什么要使用无类型常量呢 因为在Go语言中 两个类型即便拥有相同的底层类型 也仍然是不同的数据类型 因此不能在一个表达式中进行运算
1 | type myInt int |
Go在处理不同类型的变量间运算时 不支持隐式的类型转换
若要解决上面的编译错误 则必须进行显示类型转换
1 | type myInt int |
同理 将有类型常量和变量一起运算时 也要遵循此规则
若两个类型不同 也会报错
1 | type myInt int |
必须显式类型转换后才能通过编译
1 | type myInt int |
无类型常量简化代码
1 | type myInt int |
由此可见 5 3.14 syh 无需类型转换就可以直接赋值给j f str 等价于下面的代码
1 | var j myInt = myInt(5) |
因此无类型常量使混合数据类型运算变的更加灵活 代码也有所简化
无类型常量同样也拥有自己的默认类型
1 | 无类型的布偶常量 bool |
若常量被赋值给无类型变量 or 接口变量
常量的默认类型对于确定无类型变量的类型及接口对应的动态类型是至关重要的
1 | const ( |
iota实现枚举常量
枚举常量
C/C++中枚举常量的定义类型如下
1 | enum Weekday { |
而Go中没有提供定义枚举常量的语法 通常使用常量来定义枚举常量
1 | const ( |
同时 Go的const语法还提供了 “隐式重复前一个非空表达式” 的机制
1 | const ( |
尽管常量定义的后两行没有显式的赋初值 但Go编译器将其隐式使用第一行的表达式 因此上述代码等价为
1 | const ( |
iota
iota是Go的一个预定义标识符 表示const声明块中每个常量所处位置在块中的偏移量
同时每一行中的iota自身也是一个无类型常量 可以自动参与不同类型的求值运算 而无须进行显式类型转换
下面是Go标准库中sync/mutex.go中的一段枚举常量的定义
1 | // $GOROOT/src/sync/mutex.go |
第一行 mutexLocked = 1 <<iota 因为iota表示的是所处位置在const块中的偏移量 因此第一行的iota=0 所以mutexLocked = 1 <<iota = 1<<0 = 1
第二行 mutexWoken没有显式的赋予初值 所以会隐式重复前一个非空表达式 即等价于 mutexWoken = 1<<iota 而在第二行中的iota=1 所以mutexWoken = 1<<iota = 1<<1 = 2
第三行 同理 mutexStarving没有显式的赋予初值 所以等价于mutexStarving = 1<<iota 而在第三行中的iota=2 所以mutexStarving = 1<<iota = 1<<2 = 4
第四行 mutexWaiterShift = iota 第四行中的iota=3 因此mutexWaiterShift = iota = 3
位于同一行的iota即便出现多次 其值也是一样的
1 | const ( |
如果要略过iota = 0 而从iota = 1开始正式定义枚举常量 可以效仿下面的代码
1 | // $GOROOT/src/syscall/net_js.go,go 1.12.7 |
如果要定义非连续枚举值 也可以使用类似方式略过某一枚举值
1 | const ( |
iota使得Go在枚举常量定义上的表达力大增
iota预定义标识符能够以更为灵活的形式为枚举常量赋初值 在C++中就不那么灵活
1 | enum Season { |
Go的枚举常量不限于整型值 还可以定义浮点型的枚举常量 而C++就无法定义浮点类型的enum Go之所以可以定义浮点型是因为Go的无类型常量
1 | const ( |
iota使得维护枚举常量更加容易
传统的声明枚举变量方式为
1 | const ( |
常量按照首字母顺序排序。假如我们要增加一个颜色Blue,根据字母序,这个新常量应该放在Red的前面,但这样一来,我们就需要手动将从Red开始往后的常量的值都加1,十分费力
尽量定义零值可用的类型
C99规范对局部变量的规则是: 若一个变量是在栈上分配的局部变量 且在声明时未对其进行显式的初始化 那么它的值就是不确定的
因此Go在设计初就对变量默认值进行了规范
Go中的每个原生类型都有其默认值即零值
1 | 所有整形类型 0 |
并且 Go的零值初始是递归的 即数组 结构体等类型的零值初始化就是对其组成元素逐一进行零值初始
零值可用
零值可用即没有进行显式初始化的变量可以无需赋值即可直接进行操作
例如 切片
1 | var zeroSlice []int |
例如 通过nil指针调用方法
1 | // chapter3/sources/call_method_through_nil_pointer.go |
声明一个net.TCPAddr类型的指针变量p 由于未对其显示初始化 指针变量p会被赋值为nil
在标准输出上输出该变量 fmt.Println()会调用p.String() 再来看看TCPAddr这个类型的String方法实现
1 | // $GOROOT/src/net/tcpsock.go |
我们可以看到Go标准库在定义TCPAddr类型及方法充分考虑了零值可用 使得通过值为nil的TCPAddr指针变量依然可以调用String方法
Go标准库中sync.Mutex和bytes.Buffer也是充分践行了零值可用
先来看看sync.Mutex 在C中 想要使用线程互斥锁需要先初始化 然后才能上锁解锁
1 | pthread_mutex_t mutex; // 不能直接使用 |
在Go中 直接使用即可 可以省略掉对Mutex的初始化
1 | var mu sync.Mutex |
bytes.Buffer也是如此 无须对bytes.Buffer类型的变量b进行任何显式初始化 即可通过b调用Buffer类型的方法进行写入操作
1 | // chapter3/sources/bytes_buffer_write.go |
这是因为bytes.Buffer结构体用于存储数据的字段buf是支持零值可用的切片类型
1 | // $GOROOT/src/bytes/buffer.go |
没有提供零值可用的特例
在append场景下 零值可用的切片类型不能通过下标形式操作数据
1 | var s []int |
map也没有提供零值可用
1 | var m map[string]int |
零值可用的类型要注意尽量避免值传递 可以通过指针方式传递
1 | var mu sync.Mutex |
为变量赋予适当的初值可保证正确的状态参与后续计算
有些时候 零值并非是最好的选择 我们有必要为变量赋予适当的初值以保证其后续以正确的状态参与业务流程计算 尤其是Go中的一些复合类型变量 例如 结构体 数组 切片 map
对于复合类型变量 最常见的值构造方式是对其内部进行逐个赋值 例如
1 | var s myStruct |
但这样的值构造方式让代码显得很繁琐
Go提供的复合字面值(composite literal)语法可以作为复合类型变量的初值构造器
1 | s := myStruct{"tony", 23} |
复合字面值由两部分组成 一部分是类型 比如上述示例代码中赋值操作符右侧的myStruct [5]int []int map[int]string
另一部分是由大括号包裹的字面值 这里的字面值形式仅仅是Go复合字面值作为值构造器的基本用法 下面来看复合字面值对于不同复合类型的高级用法
结构体复合字面值
Go推荐使用field:value的复合字面值形式对struct类型变量进行值构造 这种值构造方式可以降低结构体类型使用者与结构体类型设计者之间的耦合
在Go标准库中 通过field:value格式的复合字面值进行结构体类型变量初值构造的例子比比皆是
1 | // $GOROOT/src/net/http/transport.go |
这种field:value形式的复合字面值初值构造器颇为强大 field:value形式字面值中的字段可以以任意次序出现 未显式出现在字面值的结构体中的字段将采用其对应类型的零值
以上述的pipe类型为例 Pipe函数在使用复合字面值对pipe类型进行初值构造时
仅对wrCh rdCh和done进行了field:value形式的显式赋值 这样pipe结构体中的其他变量的值将为其类型的初值 如wrMu
从上面例子中还可以看到 通过在复合字面值构造器的类型前面增加& 可以得到对应类型的指针类型变量 如上面例子中的变量p的类型即为Pipe类型指针
复合字面值作为结构体值构造器的大量使用 使得即便采用类型零值时我们也会使用字面值构造器形式
1 | s := myStruct{} // 常用 |
而较少使用new这一个Go预定义的函数来创建结构体变量实例
1 | s := new(myStruct) // 较少使用 |
值得注意的是 不允许将从其他包导入的结构体中的未导出字段作为复合字面值中的field 这会导致编译错误
数组/切片复合字面值
与结构体类型不同 数组/切片使用下标(index)作为field:value形式中的field 从而实现数组/切片初始元素值的高级构造形式
1 | numbers := [256]int{'a': 8, 'b': 7, 'c': 4, 'd': 3, 'e': 2, 'y': 1, 'x': 5} |
不同于结构体复合字面值较多采用field:value形式作为值构造器 数组/切片由于其固有的特性 采用index:value为其构造初值 主要应用在少数场合 比如为非连续(稀疏)元素构造初值(如上面示例中的numbers fnumbers) 让编译器根据最大元素下标值推导数组的大小(如上面示例中的fnumbers)
另外在编写单元测试时 为了更显著地体现元素对应的下标值 可能会使用index:value形式来为数组/切片进行值构造 如上面标准库单元测试源码中的data和sdata
map复合字面值
相较于结构体 数组 切片相比 map类型变量使用复合字面值作为初值构造器就显得十分自然 因为map具有原生的key:value形式
1 | //$GOROOT/src/time/format.go |
对于数组/切片而言 当元素为复合类型时 可以省去元素复合字面量中的类型 例如
1 | type Point struct { |
但对于map类型而言 Go1.5版本后 当key或value的类型为复合类型时 可以省去key或value中的复合字面量的类型
1 | //Go1.5版本之前 |
对于零值不适用的场景 我们要为变量赋予一定的初值 对于复合类型 应该首选Go提供的复合字面值座位初值构造器 对于不同复合类型 要记住以下几点
1 | 1. 使用field:value形式的复合字面值为结构体类型的变量附初值 |
了解切片的原理并高效使用
Go的切片相比数组 提供了更高效更灵活的数据序列访问接口
先了解数组
Go的数组是一个固定长度 容纳同类型元素的连续序列 因此Go数组类型具有两个属性: 元素类型 数组长度 这两个属性都相同的数组类型上是等价的 比如以下变量a b c对应的数组类型是三个不同的数组类型
1 | var a [8]int |
变量a b数组长度相同 但元素类型不同
变量a c元素类型相同 但数组长度不同
C语言中 数组变量名视为指向第一个元素的指针 但在Go中数组变量名表示整个数组 所以Go中传递数组是纯粹的值拷贝 对于元素类型长度较大或者元素个数很多的数组来说 直接以数组类型参数传递到函数中会有不小的性能损耗 很多人会使用数组指针来定义函数参数 然后将数组地址传进函数 这样的确可以避免性能损耗 但这是C的习惯 在Go中使用切片就可以做到
切片基本原理
Go中 数组更多是退居幕后扮演底层存储空间的角色 而切片则在前台表演 为底层的数组存储打开一个访问的接口
1 | var u[10]byte |
切片之所以能在函数参数传递中避免较大性能损耗 是因为切片固定大小 无论底层的数组元素是什么类型 无论切片打开的窗口有多大
下面是Go运行时(runtime)层面的内部表示
1 | //$GOROOT/src/runtime/slice.go |
在运行中 每个切片变量都是一个runtime.slice结构体类型的实例
1 | s := make([]byte, 5) //创建切片实例s |
通过上述语句创建切片 编译器自动为切片建立一个底层数组 [5]byte
若没有在make中指定cap参数 那么cap=len 即编译器建立的数组长度为len
可以通过语法u[low:high]创建对已存在数组进行操作的切片 被称为数组的切片化slicing
1 | u := [10]byte{11,12,13,14,15,16,17,18,19,20} |
切片s内部中 array为{14,15,16,17,18,19,20} len=4 cap=7
切片s打开了一个操作数组u的窗口 通过s看到的第一个元素是u[3] 通过s能看到并操作的数组元素个数为4个(high-low) 切片容量值cap取决于底层数组的长度 从切片s的第一个元素s[0]即u[3]到数组末位共有7个存储元素的槽位 因此cap为7
切片s1 s2 s3都是数组u的描述符 因此无论通过哪个切片对数组进行的修改操作都会反映到其他切片中 例如将s3[0]置为24 那么s1[2]也会变为24 因为s3[0]直接操作的是底层数组u的第四个元素u[3]
还可以通过语法s[low:high]基于已有切片创建新的切片 这被称为切片的reslicing
新创建的切片与原切片同样是共享底层数组的 并且通过新切片对数组的修改也会反映到新切片中
当切片作为函数参数传递给函数时 实际传递的是切片的内部表示 也就是上面的runtime.slice结构体实例 因此无论切片描述的底层数组有多大 切片作为参数传递带来的性能损耗都是很小且恒定 甚至可忽略不计 这就是Go中函数在参数传递更多使用切片而不用数组指针的原因之一 切片还可以提供比指针更为强大的功能 例如下表访问 边界溢出校验 动态扩容 而指针在Go中受到了限制 例如不支持指针算数运算
切片的高级特性:动态扩容
切片类型是部分满足零值可用理念的 即零值切片可以通过append预定义函数进行元素赋值操作
1 | var s []byte //s被赋予零值nil |
因为初值为零值 s这个切片并没有绑定对应的底层数组 而经过了append操作后 s才绑定了属于它的底层数组 为了观察切片s是如何动态扩容的 打印出每次append操作后切片s的len和cap值
1 | var s []int |
观察可得 切片s的len值线性增长 但cap值却非线性变化 因为append会根据切片对底层数组容量的需求来对底层数组进行动态调整
每次append时 若发现cap已经不足以给len使用 就会重新分配原cap两倍的容量 把原切片里已有的内容全部迁移过去 新分配的空间也是连续的 但不一定直接在原切片内存地址处扩容 也有可能是新的内存地址
append会根据切片的需要 在当前底层数组容量无法满足的情况下 动态分配新的数组 新数组长度按一定算法扩展($GOROOT/src/runtime/slice.go中的growslice函数) 一般为原底层数组长度的2倍 新数组建立后 append会把旧数组中的数据全部复制到新数组中 之后新数组会成为切片的底层数组 旧数组后续会被垃圾回收掉
但当通过语法u[low:high]进行数组切片化而创造的切片 一旦u的cap触碰到数组的上界 再对切片进行append操作的时候 切片u就会和原数组解除绑定
1 | package main |
运行后结果为
1 | array: [11 12 13 14 15] |
添加25后 切片的元素已经触碰到了底层数组的边界 若要在添加新元素 append会发现底层数组无法满足添加需求 所以就会新创建一个底层数组 数组长度为cap(s)的2倍 即8 并将原切片的元素复制到新数组中 在此之后即使再修改切片中的元素值 原底层数组u的元素也不会改变 因为此时切片s已经和原数组u解除绑定了
尽量使用cap参数创建切片
append操作让切片类型部分满足了零值可用的理念 但从append原理中 能看到重新分配底层数组并复制元素的开销是很大的 尤其是元素特别多的情况下 所以要有效的减少或避免内存分配和复制的开销的一个方法是 根据切片的使用场景对切片的容量规模进行估计 并在创建新切片时将预估出的切片容量数据以cap参数的形式传递给内置函数make
1 | s := make([]T,len,cap) |
根据性能测试可知 使用带cap参数创建的切片进行append操作的平均性能是不带cap参数切片的4倍左右
了解map实现原理并高效使用
在Go中 map表示一组无序的键值对(key-value) map对value的类型没有限制 但对key的类型有严格要求:key的类型应该严格定义了作为== !=两个操作符的操作数时的行为 因此 函数 map 切片 不能作为map的key类型
map类型不支持零值可用 未显式赋初值的map类型变量的零值为nil 对处于零值状态的map变量进行操作将会导致panic
1 | var m map[string]int // m = nil |
必须对map类型变量进行显式初始化后才能使用它 和切片一样有两种创建方式 一种是使用复合字面值 另一种是使用内置函数make
1 | //使用复合字面值创建map类型变量 |
和切片一样 map也是引用类型 将map类型变量作为函数参数传入不会有很大的性能损耗 并且在函数内部对map变量的修改在函数外部也是可见的
1 | func foo(m map[string]int) { |
函数foo中对m进行了修改 这些修改在foo外也可见
map基本操作
- 插入数据
面对一个非nil的map类型变量 可以插入符合map类型定义的任意键值对 Go会负责map内部的内存管理 除非系统内存耗尽 否则不用担心向map中插入数据的数量
1 | m := make(map[k]v) |
若key已经存在于map中 则该插入操作的新值会覆盖旧值
1 | m := map[string]int { |
- 获取数据个数
和切片一样 map也可以通过内置函数len()来获取已经存储的数据个数
1 | m := map[string]int { |
- 查找和数据读取
map更多用在查找数据和读取数据的场合 所谓查找就是判断某个key是否存在于map中 可以用 “comma ok”惯用法来进行查找
1 | _, ok : m["key"] |
以上代码并没有关心某个key对应的value 而只关心某个key是否存在map中 因此能使用空标识符(Blank identifier)忽略了可能返回的数据值 而只关心ok的值是否为true(表示存在于map中)
若要读取key对应的value值 可能会这样书写
1 | m := map[string]int { |
当key1存在的时候 代码没有问题 但当key3不存在的时候 v仍然被赋予了一个”合法”的值0 即value的类型int的零值 这种情况无法判断这个0是key3对应的value值 还是不存在而返回的0 为此 我们需要 “comma ok”惯用法
1 | m := map[string]int |
需要通过ok的值来判断key是否存在于map中 只有当ok = true 所获得的value值才是被需要的
- 删除数据
借助内置函数delete来删除数据
1 | m := map[string]int { |
即使要删除的数据在map中不存在 delete也不会导致panic
- 遍历数据
可以像切片一样 使用 for range来遍历map中的数据
1 | func main() { |
上面的输出给出的表象是迭代器按照map元素的插入次序依次遍历输出 然而并不是如此
1 | package main |
对同一个map进行多次遍历 输出的元素次序并不相同 这是因为Go在初始化map迭代器时对起始位置做了随机处理 因此千万不要依赖遍历map所得到的的元素次数
若需要一个稳定的元素遍历次序 比较通用的做法是使用另一个数据结构来按需要的次序保存key 例如使用切片
1 | func doIteration(sl []int, m map[int]int) { |
map的内部实现
Go在运行时使用一张哈希表来实现抽象的map类型 运行时实现map所有功能包括查找 插入 删除 遍历
在编译阶段Go的编译器会将语法层面的map操作冲携程运行时对应的函数调用 下面是大致的对应关系
1 | // $GOROOT/src/cmd/compile/internal/gc/walk.go |
尽量使用cap参数创建map
从map的自动扩容原理了解到 如果创建map时没有给予足够多的bucket空间 就会随着map中元素数量的增多导致频繁扩容 降低访问map的性能 因此 最好对map的容量做出粗略的估算 并且使用cap参数来对map进行初始化
1 | package main |
1 | Running tool: D:\Code\Go\bin\go.exe test -benchmem -run=^$ -bench ^(BenchmarkMapInitWithoutCap|BenchmarkInitWithCap)$ go_learning/src/chapter3 |
可以看出使用cap参数创建的map实例平均写性能是不使用cap参数的2倍
map总结
不要依赖map的元素遍历顺序
map不是线程安全的 不支持并发写
不要尝试获取map中元素(value)的地址
尽量使用cap参数来make创建map实例 提升map平均访问性能 减少频繁扩容带来的损耗
了解string实现原理并高效使用
Go语言的字符串类型
1 | const ( |
Go的string类型特点
- string类型的数据是不可变的
一旦声明了一个string类型的标识符 无论是常量还是变量 该标识符所指代的数据在整个程序的生命周期内便无法更改
1 | //chapter3/sources/string_immutable1.go |
该程序运行结果如下
1 | $ go run string_immutable1.go |
在上面的例子中 试图将string转换为一个切片 并通过该切片对其内容进行修改
对string切片化后 Go编译器会为切片变量重新分配底层存储而不是公用string的底层存储
因此对切片的修改并未对原string产生影响
1 | //chapter3/sources/string_immutable2.go |
该程序运行结果如下
1 | origin string: hello |
上面的例子中 试图通过unsafe指针指向string在运行时内部表示结构中的数据存储块的地址 然后通过指针修改那块内存中存储的数据
运行后出现报错 因为只能对string底层数据存储进行只读操作 一旦试图修改那块区域的数据 就会得到SIGBUS的运行错误
- string类型支持零值可用
Go的string类型支持零值可用 无须像C语言那样考虑结尾\0 因此Go的string零值为 “” 长度为0
1 | var s string |
- string类型获取长度的时间复杂度为O(1)
Go的string类型数据是不可变的 因此一旦有了初值 那块数据就不会改变 其长度也不会改变 Go将这个长度作为一个字段存储在string类型的内部表示结构中 这样获取string长度的操作len(s)实际上就是直接读取那个长度值 这是一个代价极低的O(1)操作
- string类型支持+/+=操作符进行字符串连接
1 | s := "Ruojhen, " |
- string类型支持比较关系操作符 == != >= <= > <
1 | s1 := syh |
- 对非ASCII字符提供原生支持
Go的字符集默认为Unicode 这些字符默认以UTF-8编码存储在内存中 中文字符大多数都使用三字节表示
1 | package main |
- 原生支持多行字符串
靠反引号来构造多行字符串
1 | const s = `总结 LRU 是由一个 map 和一个双向链表组成的数据结构。 |
字符串的内部表示
1 | //$GOROOT/src/runtime/string.go |

